About me |
|
I am a Computer Vision PhD student with the Intelligent Visual Analytics Lab (IVAL) at Mohamed bin Zayed University of Artificial Intelligence (MBZUAI), advised by Prof. Salman Khan and Prof. Fahad Khan. I completed my MSc in Computer Vision at MBZUAI. My research focuses on vision-language models (VLMs) for reasoning and OCR, with an emphasis on efficient and reliable real-world deployment. I am currently a Research Scientist Intern at LG AI Research. Previously, I was a Research Scientist Intern at Parameter Lab (in collaboration with NAVER LABS), an Applied Scientist at Monta AI, and a Software Engineer at And Africa Co., Ltd., with earlier ML internship experience at Scoville. Broadly, I build efficient, fast, and robust multimodal methods across OCR, VLMs, and on-device/mobile deployment. Email / Resume / Google Scholar / Github / Linkedin |

|
Selected Publications |
|
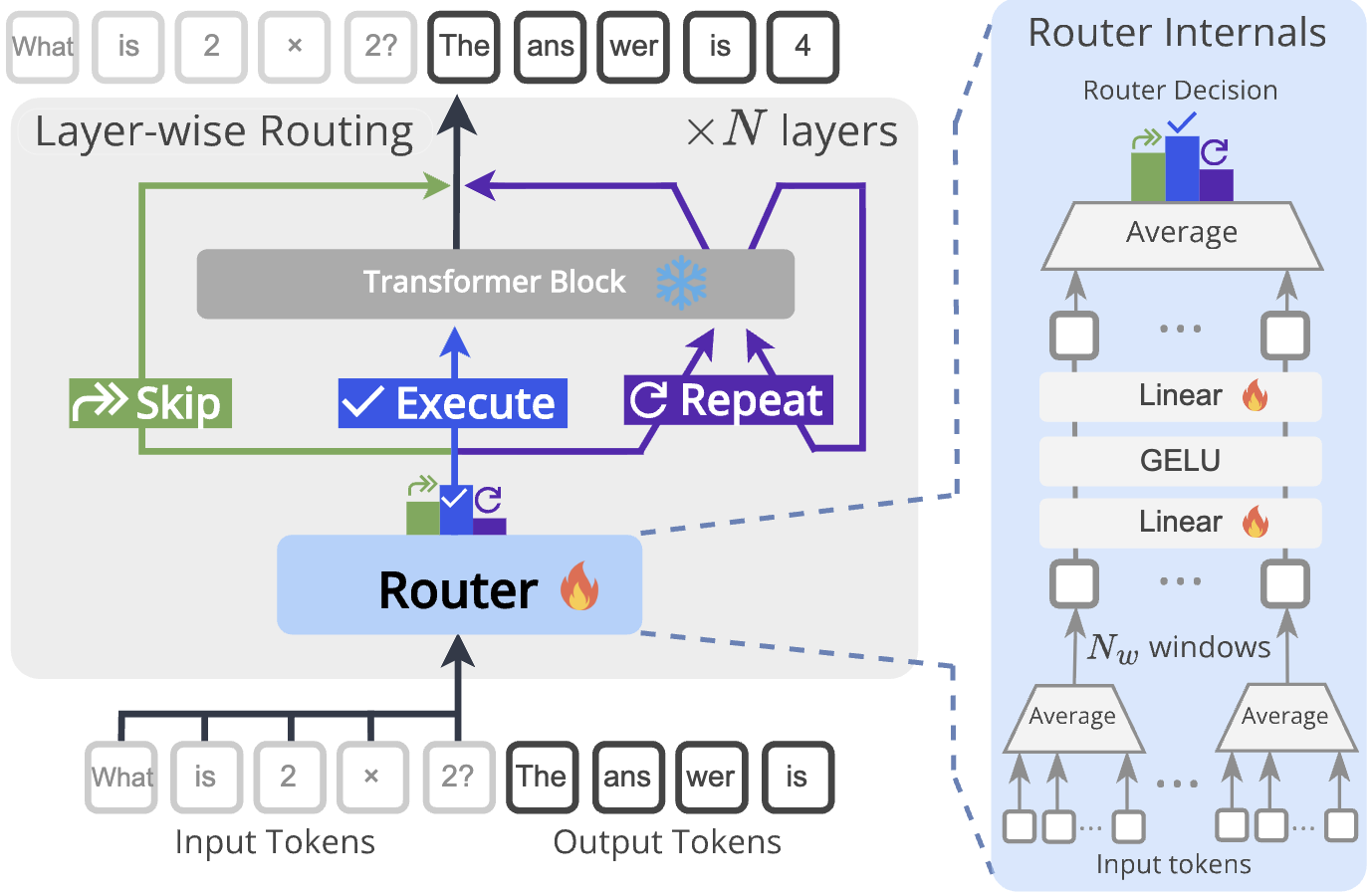
Dr.LLM: Dynamic Layer Routing in LLMs
Ahmed Heakl, Martin Gubri, Salman Khan, Sangdoo Yun, Seong Joon Oh ICLR 2026 Paper / Code Dr.LLM retrofits pretrained LLMs with lightweight per-layer routers that dynamically skip/execute/repeat layers under a compute budget, improving efficiency while preserving accuracy via supervised routing derived from MCTS. |
|
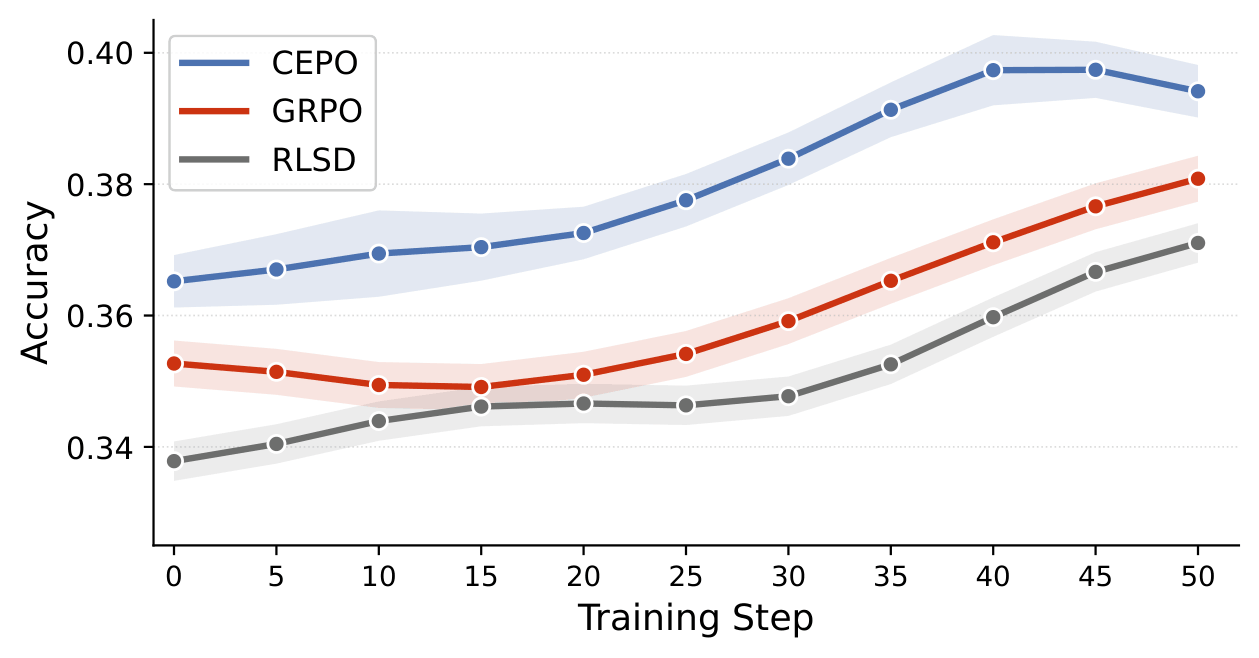
CEPO: RLVR Self-Distillation using Contrastive Evidence Policy Optimization
Ahmed Heakl, Abdelrahman M. Shaker, Youssef Mohamed, Rania Elbadry, Omar Fetouh, Fahad Khan, Salman Khan Under Submission Paper / Code CEPO is a token-level credit assignment method for RLVR that replaces uniform reward signals with a contrastive ratio between correct and wrong answer teachers (drawn from rejected rollouts at no extra cost), focusing gradient updates on the tokens that actually decide correctness. In just 50 training steps, CEPO improves over GRPO by +2.26% at 2B and +3.13% at 4B scale across five multimodal math reasoning benchmarks; distribution matching alternatives (OPSD, SDPO) collapse below the untrained baseline, confirming the information leakage CEPO is designed to avoid. |
|
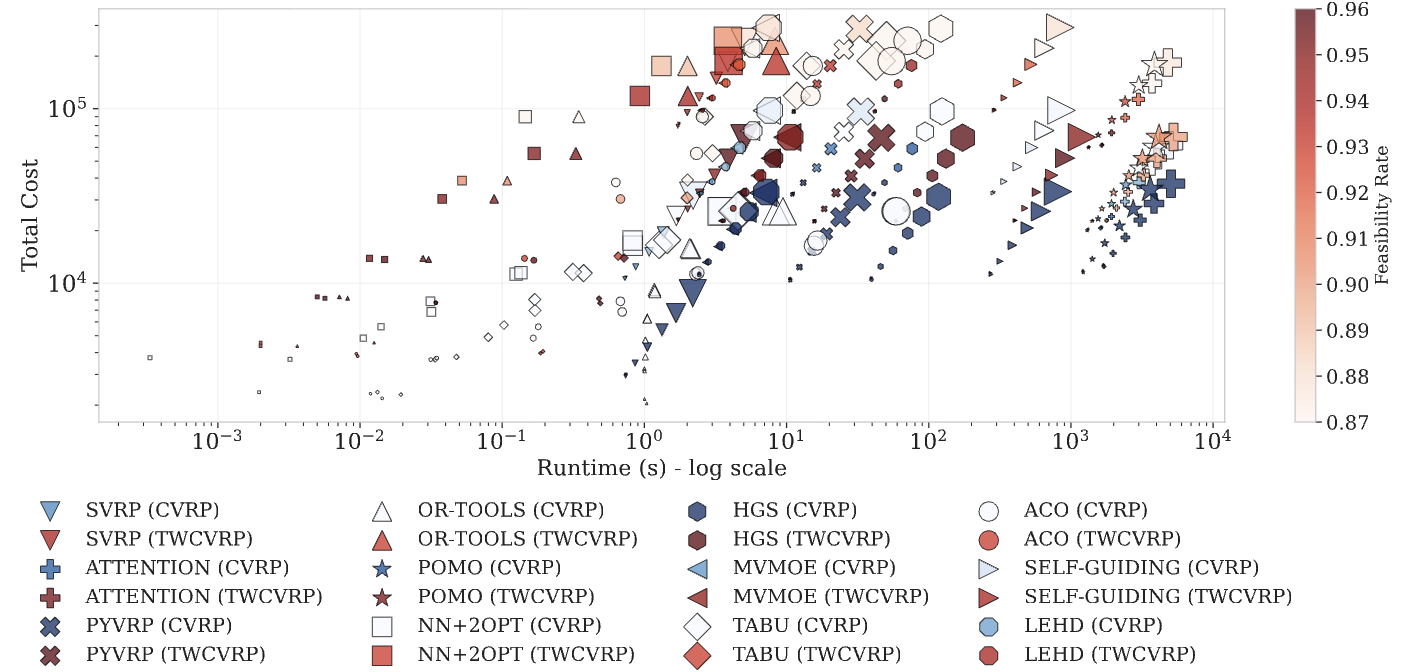
SVRPBench: A Realistic Benchmark for Stochastic Vehicle Routing Problem
Ahmed Heakl*, Yahia Salaheldin Shaaban*, Martin Takac, Salem Lahlou, Zangir Iklassov NeurIPS 2025 — Datasets and Benchmarks Paper / Code / Dataset SVRPBench is an open-source benchmark of 500+ urban-scale stochastic VRP instances featuring time-dependent congestion, probabilistic delays, and heterogeneous time windows, together with a full evaluation suite for learning-based solvers. |
|
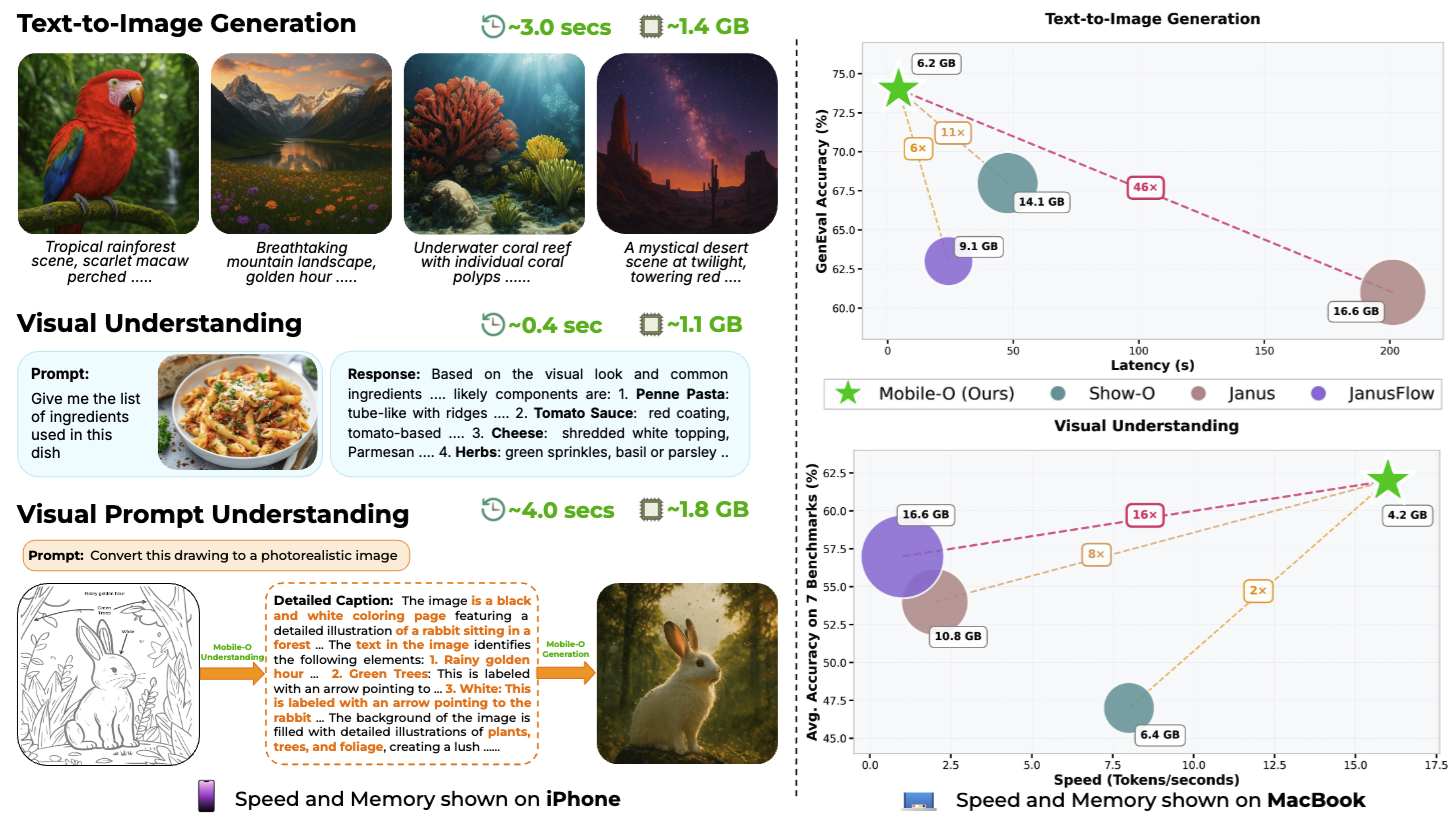
Mobile-O: Unified Multimodal Understanding and Generation on Mobile Device
Abdelrahman Shaker*, Ahmed Heakl*, Jaseel Muhammad, Ritesh Thawkar, Omkar Thawakar, Senmao Li, Hisham Cholakkal, Ian Reid, Eric P. Xing, Salman Khan, Fahad Shahbaz Khan Under Submission Paper / Code / Mobile App Mobile-O is a compact, efficient unified vision–language–diffusion model that performs both multimodal understanding (VQA, OCR, reasoning) and image generation within a single architecture, while running entirely on-device. It is designed specifically for mobile and edge deployment, achieving real-time performance with a small memory footprint. |
|
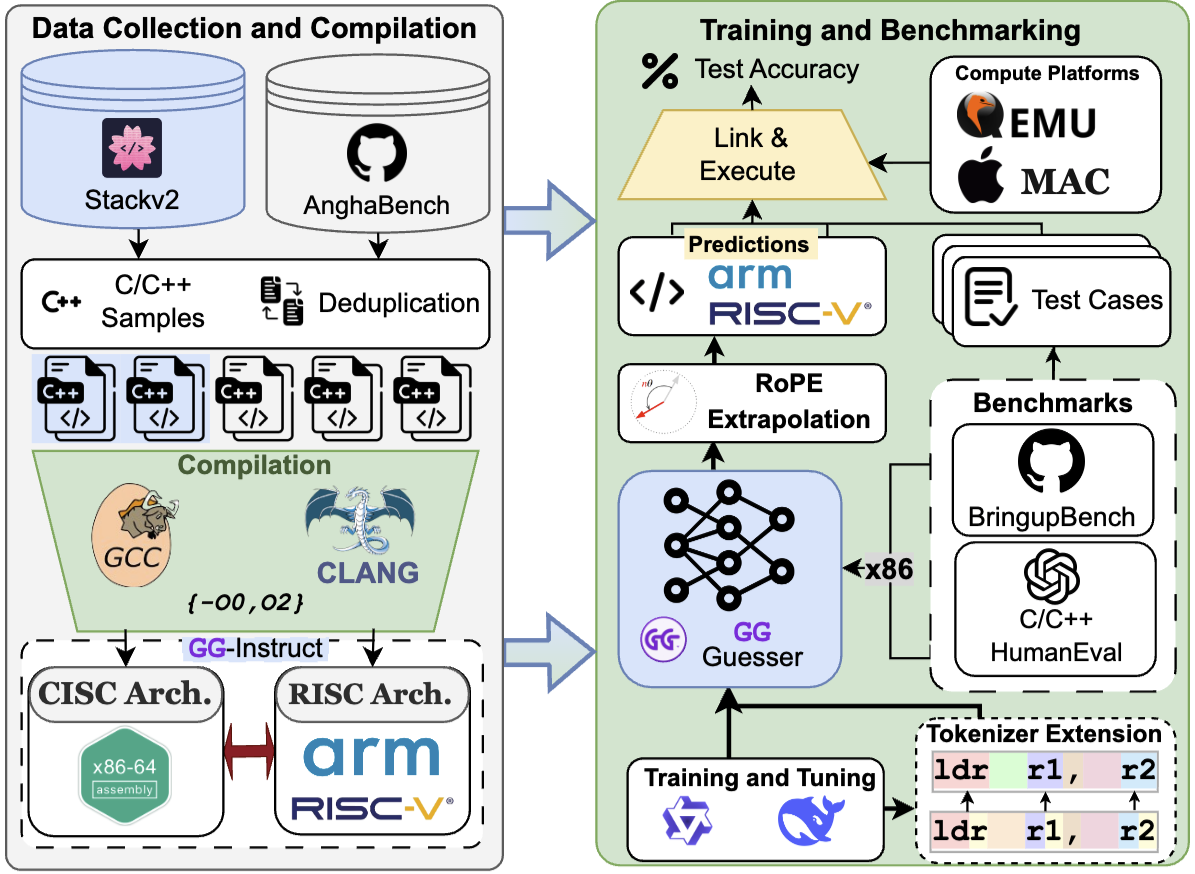
GG: An LM Approach for CISC-to-RISC Transpilation with Testing Guarantees
Ahmed Heakl, Sarim Hashmi, Chaimaa Abi, Celine Lee, Abdulrahman Mahmoud EMNLP 2025 — Findings Paper / Code / Datasets and Models We introduce Guaranteed Guess (GG), a test-driven CISC-to-RISC transpiler using LLMs. GG achieves 99.4% functional accuracy on x86→ARMv8 translation and improves runtime and memory versus strong baselines through verification-centric generation and refinement. |

|
KITAB-Bench: Multi-Domain Arabic OCR and Document Understanding Bench
Ahmed Heakl*, Abdullah Sohail*, Mukul Ranjan*, Rania Hossam*, Ghazi Shazan Ahmad, Mohamed El-Geish, Omar Maher, Zhiqiang Shen, Fahad Khan, Salman Khan ACL 2025 — Findings Paper / Dataset / Code KITAB-Bench contains 8,809 Arabic pages spanning 9 domains and 36 sub-domains to evaluate OCR and document understanding. The benchmark highlights large gains from VLM-based OCR (≈60% lower character error than traditional OCR) while PDF-to-Markdown conversion peaks around ≈65%. |

|
LlamaV-o1: Rethinking Step-by-step Visual Reasoning in LLMs
Omkar Thawakar*, Dinura Dissanayake*, Ketan More*, Ritesh Thawkar*, Ahmed Heakl*, Noor Ahsan*, Yuhao Li, Mohammed Zumri, Jean Lahoud, Rao Muhammad Anwer, Hisham Cholakkal, Ivan Laptev, Mubarak Shah, Fahad Shahbaz Khan, Salman Khan ACL 2025 — Findings Paper / Code / Benchmark / Model We propose a curriculum framework and a benchmark with 4k+ reasoning steps across 8 categories for step-by-step visual reasoning. LlamaV-o1 improves over Llava-CoT by 3.8% while delivering ~5× faster inference. |

|
SAHM: A Benchmark for Arabic Financial and Shari'ah-Compliant Reasoning
Rania Elbadry, Sarfraz Ahmad, Ahmed Heakl, Dani Bouch, Momina Ahsan, Muhra AlMahri, Marwa Elsaid khalil, Yuxia Wang, Salem Lahlou, Sophia Ananiadou, Veselin Stoyanov, Jimin Huang, Xueqing Peng, Preslav Nakov, Zhuohan Xie ACL 2026 (Oral) Paper / Code / Dataset Leaderboard SAHM is the first Arabic financial NLP benchmark, spanning seven tasks, AAOIFI standards QA, fatwa-based QA/MCQ, accounting and business exams, financial sentiment analysis, extractive summarization, and event-cause reasoning, with 14,380 expert-verified instances from authentic regulatory, juristic, and corporate sources. Evaluating 20 LLMs, we show that Arabic fluency does not imply financial reasoning, and that domain-adapted 7–8B models can surpass GPT-5 and match 72B baselines. |
|
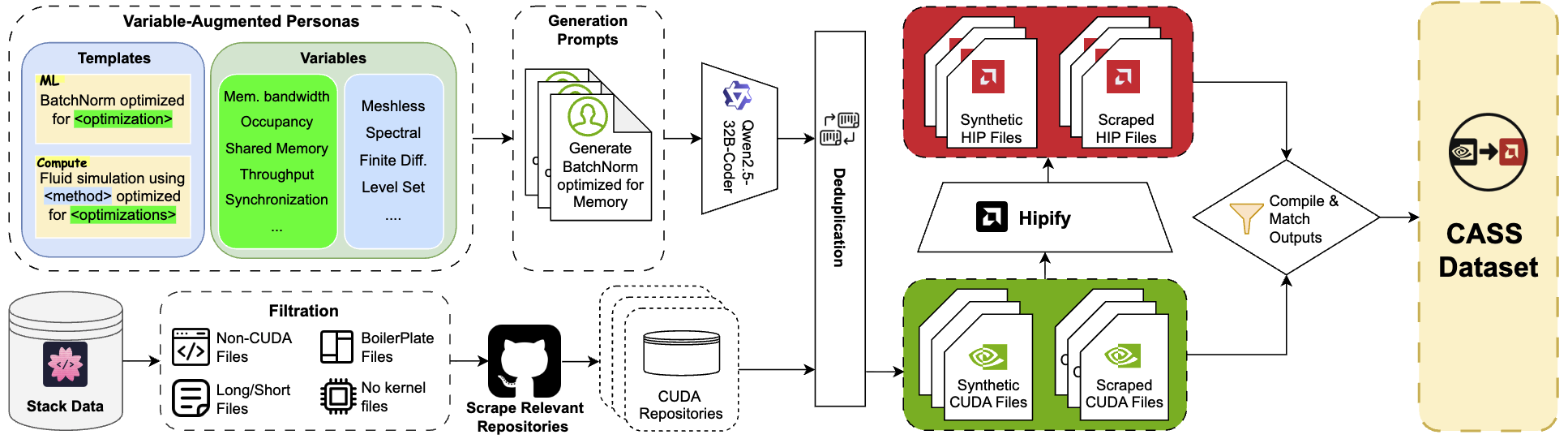
CASS: Nvidia to AMD Transpilation with Data, Models, and Benchmark
Ahmed Heakl, Sarim Hashmi, Gustavo Bertolo Stahl, Seung Hun Eddie Han, Salman Khan, Abdulrahman Mahmoud ACL 2026 Paper / Code / Dataset CASS introduces the first large-scale dataset and benchmark (70k samples) for transpilation between Nvidia CUDA and AMD HIP/RDNA3 at both source and assembly levels. We train domain-specialized LLMs (up to 7B) that achieve strong functional preservation and substantially improve transpilation accuracy on challenging low-level code. |

|
VideoMolmo: Spatio-Temporal Grounding Meets Pointing
Ghazi Shazan Ahmad*, Ahmed Heakl*, Hanan Gani, Abdelrahman Shaker, Zhiqiang Shen, Fahad Shahbaz Khan, Salman Khan ACL 2026 - Findings Paper / Code / VPoS-Bench VideoMolmo is a spatio-temporal grounding framework that combines LLM-driven pointing with mask fusion (via SAM2). We introduce temporal attention and bidirectional mask propagation, curate a large video-caption dataset with dense object points, and propose VPoS-Bench to evaluate grounding, counting, and reasoning in real-world video domains. |

|
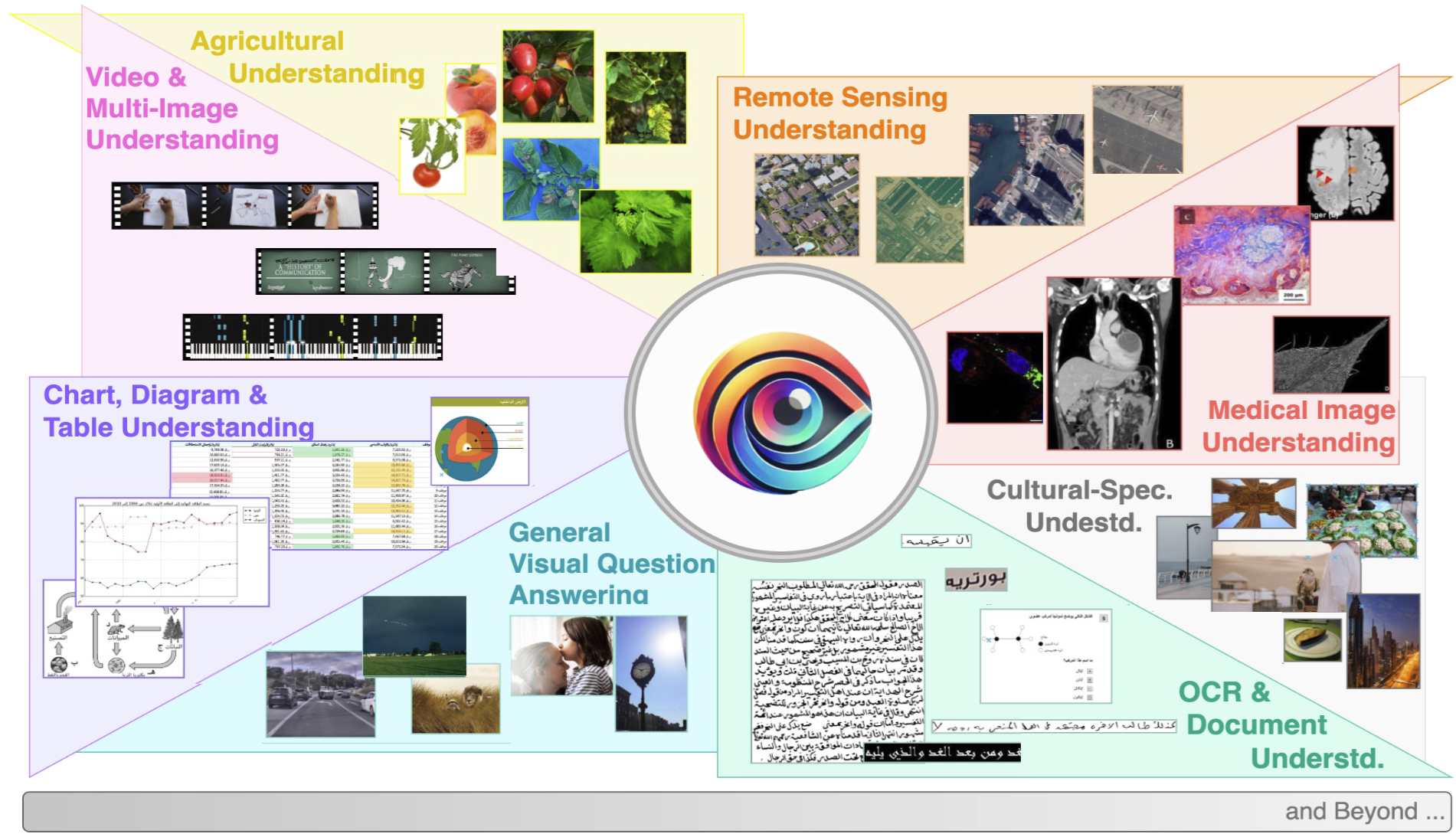
CAMEL-Bench: A Comprehensive Arabic LMM Benchmark
Sara Ghaboura*, Ahmed Heakl*, Omkar Thawakar, Ali Alharthi, Ines Riahi, Abduljalil Saif, Jorma Laaksonen, Fahad S. Khan, Salman Khan, Rao Muhammad Anwer NAACL 2025 Paper / Code CAMEL-Bench is a large-scale Arabic-centric LMM evaluation benchmark spanning diverse domains (OCR/Docs, medical, remote sensing, video, and more) with broad coverage for realistic Arabic multimodal reasoning. |
|
AIN: The Arabic INclusive Large Multimodal Model
Ahmed Heakl, Sara Ghaboura, Omkar Thawakar, Fahad Shahbaz Khan, Hisham Cholakkal, Rao Muhammad Anwer, Salman Khan Preprint Paper / Code AIN is a bilingual (Arabic/English) large multimodal model designed to close the Arabic LMM gap, targeting broad-domain multimodal understanding and strong Arabic performance across diverse tasks. |
|
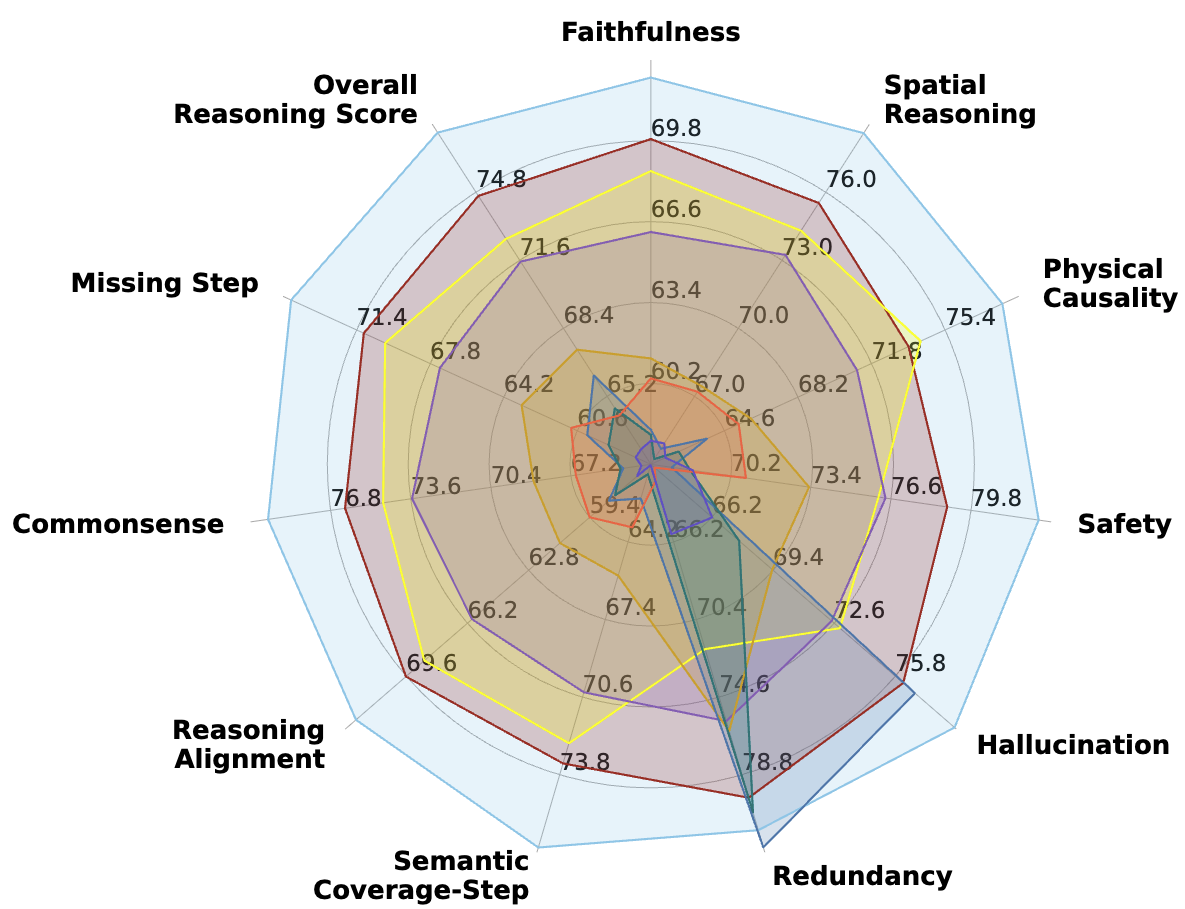
How Good are Foundation Models in Step-by-Step Embodied Reasoning?
Dinura Dissanayake, Ahmed Heakl, Omkar Thawakar, Noor Ahsan, Ritesh Thawkar, Ketan More, Jean Lahoud, Rao Muhammad Anwer, Hisham Cholakkal, Ivan Laptev, Fahad Shahbaz Khan, Salman Khan Under Review Paper / Code Introduces the FoMER benchmark to evaluate step-by-step embodied reasoning for foundation multimodal models, analyzing action validity and reasoning correctness across diverse tasks and embodiments. |
News |
Academic Service and Awards |